오늘 살펴볼 요리책 예제는 Embedding ling input입니다.
https://github.com/openai/openai-cookbook/blob/main/examples/Embedding_long_inputs.ipynb
GitHub – openai/openai-cookbook: OpenAI API 사용을 위한 샘플 및 가이드
OpenAI API 사용을 위한 샘플 및 가이드. GitHub에서 계정을 만들어 openai/openai-cookbook 개발에 기여하세요.
github.com
Open AI에서 각 모델은 입력 값 길이에 제한이 있습니다. 입력은 토큰으로 측정됩니다.
토큰에 대한 설명은 다음 페이지에서 찾을 수 있습니다.
GitHub – openai/openai-cookbook: OpenAI API 사용을 위한 샘플 및 가이드
OpenAI API 사용을 위한 샘플 및 가이드. GitHub에서 계정을 만들어 openai/openai-cookbook 개발에 기여하세요.
github.com
오늘의 예는 이 모델의 최대 컨텍스트 길이보다 긴 텍스트를 처리하는 방법을 보여줍니다.
1. 모델 컨텍스트 길이
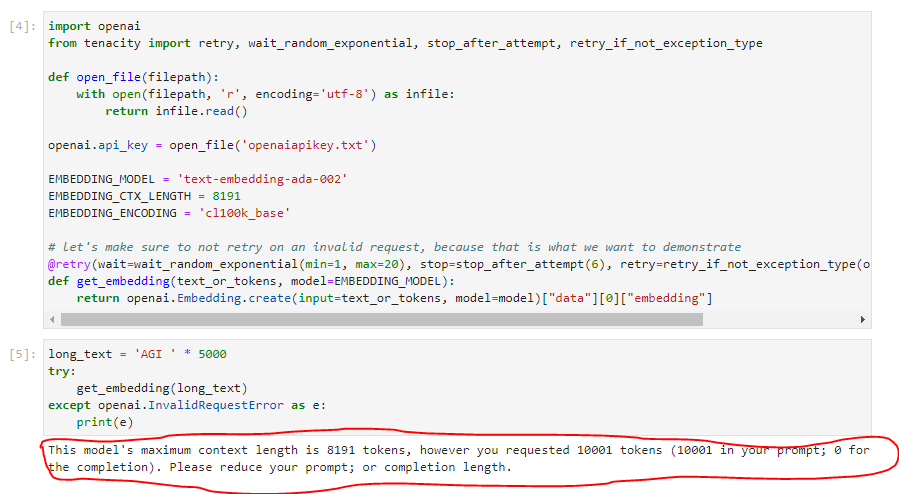
import openai
from tenacity import retry, wait_random_exponential, stop_after_attempt, retry_if_not_exception_type
EMBEDDING_MODEL = 'text-embedding-ada-002'
EMBEDDING_CTX_LENGTH = 8191
EMBEDDING_ENCODING = 'cl100k_base'
# let's make sure to not retry on an invalid request, because that is what we want to demonstrate
@retry(wait=wait_random_exponential(min=1, max=20), stop=stop_after_attempt(6), retry=retry_if_not_exception_type(openai.InvalidRequestError))
def get_embedding(text_or_tokens, model=EMBEDDING_MODEL):
return openai.Embedding.create(input=text_or_tokens, model=model)("data")(0)("embedding")먼저 openai를 가져온 다음 tenacity 모듈을 가져옵니다.
Tenacity는 런타임 중에 오류가 발생하고 종료가 발생하면 종료를 방지하고 다시 시도하고 싶을 때 사용되는 Python 모듈입니다.
이러한 모듈에서는 retry, wait_random_exponential, stop_after_attempt 및 retry_if_not_exception_type만 가져옵니다.
(이렇게 하면 @tenacity.retry라고 부르지 않고 @retry 형식을 사용할 수 있습니다.)
다음으로 Openai 모델을 설정하고 컨텍스트 길이를 8191로 설정하고 인코딩을 cl100k_base로 설정합니다.
cl100k_base는 토크나이저이고 최대 입력 토큰은 8191로 설정됩니다. 2021년 9월에 발표되었습니다.

자세한 내용은 OpenAI 가이드의 임베딩 개요 페이지를 참조하세요.
https://platform.openai.com/docs/guides/embeddings/what-are-embeddings
OpenAI API
OpenAI에서 개발한 새로운 AI 모델에 액세스하기 위한 API
platform.openai.com
그 다음에는 @retry 구문이 나옵니다. 재시도 사이의 대기 시간은 1~20초이며 최대 6회까지 시도할 수 있으며 예외 유형이 InvalidRequestError가 아닌 경우에만 재시도를 시도합니다. InvalidRequest의 경우 재시도를 해도 소용이 없다.
다음으로 get_embedding() 함수를 만들었습니다.
text_or_tokens 및 모델 이름을 입력 매개변수로 허용합니다.
그런 다음 받은 모델을 사용하여 openai.Embedding.create() API에서 해당 입력 값에 대한 포함 값을 받고 값을 반환합니다.
아직 아무 일도 일어나지 않았습니다.
long_text="AGI " * 5000
try:
get_embedding(long_text)
except openai.InvalidRequestError as e:
print(e)여기에는 long_text가 설정되어 있고 long_text에는 문자 AGI를 5,000번 반복한 값이 삽입되어 있습니다.
그리고 get_embedding()을 호출할 때 이 long_text를 전달합니다.
이 시점에서 이 호출 부분을 try로 감싸고 openai의 InvalidRequestError인 경우 이 오류 메시지를 인쇄합니다.
이 InvalidRequestError 메시지가 발생합니다.
다음 예제에서는 Openai 모델의 최대 입력 토큰을 초과하는 입력 텍스트를 사용하는 방법을 설명합니다.
첫 번째 방법은 입력 텍스트를 허용되는 최대 길이로 자르거나 두 번째 방법은 입력 텍스트를 분할하고 이 섹션을 개별적으로 둘러싸는 것입니다.
여기서 명심해야 할 한 가지는 API 사용 가격입니다.

text-embedding-ada-002 모델은 1,000개 토큰당 $0.0004입니다. 0.04센트입니다.
그럼 위에서 만든 5000개의 AGI인 long_text에 얼마나 많은 토큰이 있는지 살펴보자.

이 long_text 입력에는 총 10,001개의 토큰이 있습니다.
0.0004 X(10001 / 1000)를 수행하면 0.004개의 조명을 얻습니다.
이 모델의 최대 입력 값으로 요청해도 한 푼도 못 받습니다.
참고로 다음 페이지로 이동하면 저기에 있는 토큰 수 계산을 볼 수 있습니다.
https://platform.openai.com/tokenizer
OpenAI API
OpenAI에서 개발한 새로운 AI 모델에 액세스하기 위한 API
platform.openai.com
1. 입력한 텍스트 잘림
이것이 위에서 언급한 첫 번째 솔루션입니다. 모델이 허용하는 최대 입력 크기로 자르기만 하면 됩니다.
여기서 크기는 토큰에 의해 결정되기 때문에 먼저 입력 값이 몇 개의 토큰으로 구성되어 있는지 알아야 합니다.
위 토크나이저 나는 페이지에서 그것을했다. 10001이었습니다. 그리고 위에서 사용된 모델에서 8191 토큰이 허용되는 최대 입력입니다.
다음 방법은 이러한 방식으로 입력을 토큰화하고 분할하는 부분입니다.
import tiktoken
def truncate_text_tokens(text, encoding_name=EMBEDDING_ENCODING, max_tokens=EMBEDDING_CTX_LENGTH):
"""Truncate a string to have `max_tokens` according to the given encoding."""
encoding = tiktoken.get_encoding(encoding_name)
return encoding.encode(text)(:max_tokens)openai의 모듈 중 하나인 tiktoken 모듈을 가져옵니다.
https://github.com/openai/tiktoken
GitHub – openai/틱토큰
GitHub에서 계정을 생성하여 Openai/tiktoken 개발에 기여하십시오.
github.com
그리고 text, encoding_name 및 max_tokens를 입력 매개변수로 사용하는 truncate_text_tokens() 함수를 만들었습니다.
이 함수는 지정된 인코딩에 max_tokens를 포함하도록 문자열을 다듬는 작업을 수행합니다.
일단 인코딩을 설정합니다. tiktoken.get_encoding() 함수를 사용하고 위에서 설정한 인코딩 이름 값을 사용합니다.
EMBEDDING_ENCODING = ‘cl100k_base’
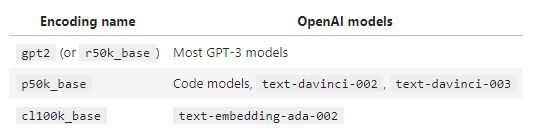
참고로 Tiktoken은 OpenAI 모델에서 사용되는 다음 세 가지 인코딩을 지원합니다.
https://github.com/openai/openai-cookbook/blob/main/examples/How_to_count_tokens_with_tiktoken.ipynb
GitHub – openai/openai-cookbook: OpenAI API 사용을 위한 샘플 및 가이드
OpenAI API 사용을 위한 샘플 및 가이드. GitHub에서 계정을 만들어 openai/openai-cookbook 개발에 기여하세요.
github.com
다음 부분은 해당 인코딩을 기준으로 max_tokens만큼 잘라서 반환하는 부분입니다.
return encoding.encode(text)(:max_tokens)
이렇게 받은 값을 출력해 보았습니다.

AGI의 반복이기 때문에 같은 숫자만 반복되는 것일 수도 있습니다.
Truncate는 뒷부분을 자르는 것을 의미합니다.
최대 한도까지만 남기고 나머지는 차단합니다.
예를 들어 이 잘린 값을 get_embedding에 보낸 길이를 인쇄했습니다.
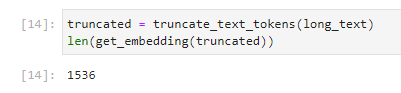
1536이 나왔습니다. 임베딩 번호의 차원입니다. len()이 사용되지 않고 출력이 변경되지 않은 경우 1536개의 정수 목록이 출력되었을 것입니다.
이는 get_embedding() 함수가 오류 없이 작동했음을 의미합니다.
지금까지 입력 값을 잘라서 제한을 초과하는 입력 값을 처리하는 방법을 살펴보았습니다.
남는 부분을 잘라내기 때문에.. 정확한 결과가 나올지 의문입니다.
tiktokens encode()(:max_tokens)로 잘린 후 openai api로 요청합니다.
이렇게 하고 청구 금액을 확인했습니다.

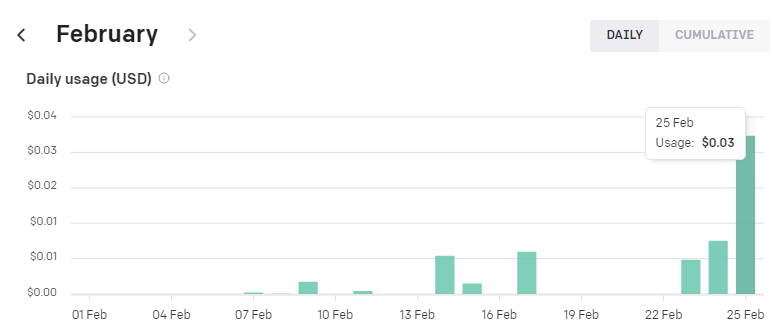
계산할 필요가 거의 없습니다.
마지막 막대 차트이고 아직 한 푼도 청구되지 않았습니다.
그 이전에 가장 긴 막대 차트는 제가 어제(02/24) 사용한 것으로 $0.01(1센트)로 계산되었습니다.
2. 입력 텍스트 청킹
Truncate는 작동하게 할 수 있지만 잠재적으로 중요한 부분을 잘라내는 것은 단점처럼 보입니다.
잘림 이외의 다른 옵션은 청크로 나누는 것입니다.
큰 입력 값을 여러 그룹으로 나누고 개별적으로 요청하여 답변을 받도록 설계되었습니다.
그렇지 않으면 이러한 청크 포함을 평균화하고 요청한 다음 응답할 수 있습니다..
이 예에서는 큰 입력을 청크로 분할하는 모듈을 사용합니다.
다음 페이지에서 이 모듈을 볼 수 있습니다.
https://docs.python.org/3/library/itertools.html#itertools-recipes
itertools – 효율적인 루프를 위한 반복자를 생성하는 함수
이 모듈은 APL, Haskell 및 SML의 구조에서 영감을 받은 일련의 반복자 빌딩 블록을 구현합니다. 각각 파이썬에 적합한 형태로 변형되었습니다. 모듈은 코어 세트를 표준화합니다…
docs.python.org
방법은 아래에서 시작됩니다.
from itertools import islice
def batched(iterable, n):
"""Batch data into tuples of length n. The last batch may be shorter."""
# batched('ABCDEFG', 3) --> ABC DEF G
if n < 1:
raise ValueError('n must be at least one')
it = iter(iterable)
while (batch := tuple(islice(it, n))):
yield batch먼저 itertools에서 islice 함수를 가져옵니다.
batched() 함수를 만들고 iterable과 n을 입력으로 사용합니다.
그런 다음 입력 데이터는 길이 n의 튜플로 일괄 처리됩니다. 마지막 스택은 n보다 작을 수 있습니다.
길이 n이 1보다 작으면 오류가 발생합니다.
raise는 오류를 발생시키는 Python 명령입니다.
이것을 사용하면 주어진 오류가 발생하고 프로그램이 중지됩니다.
https://www.w3schools.com/python/ref_keyword_raise.asp
파이썬 레이즈 키워드
W3Schools는 웹의 모든 주요 언어로 무료 온라인 자습서, 참조 및 연습을 제공합니다. HTML, CSS, JavaScript, Python, SQL, Java 등과 같은 인기 있는 주제를 다룹니다.
www.w3schools.com
다음 페이지에서 오류 유형을 확인할 수 있습니다.
https://docs.python.org/3/library/exceptions.html#ValueError
기본 제공 예외
Python에서 모든 예외는 BaseException에서 파생된 클래스의 인스턴스여야 합니다. 특정 클래스를 언급하는 except 절이 있는 try 문에서 해당 절은 모든 예외도 처리합니다…
docs.python.org
입력 값이 1 이상인 경우 iterable 입력은 iter()로 처리됩니다.
iter()는 반복자 객체를 생성하는 Python 함수입니다.
https://www.w3schools.com/python/ref_func_iter.asp
파이썬 iter() 함수
W3Schools는 웹의 모든 주요 언어로 무료 온라인 자습서, 참조 및 연습을 제공합니다. HTML, CSS, JavaScript, Python, SQL, Java 등과 같은 인기 있는 주제를 다룹니다.
www.w3schools.com
그런 다음 while 문이 실행됩니다.
islice()는 다음과 같이 작동합니다.
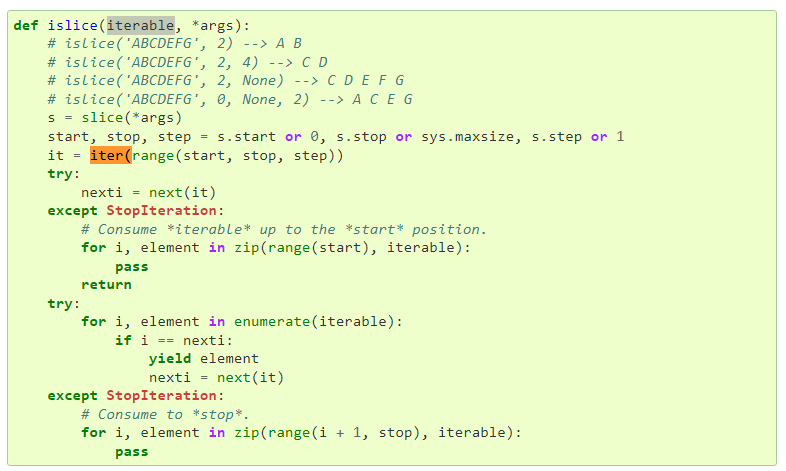
islice(it,n)은 입력 it 값을 n 단위로 슬라이스합니다. 이 값을 튜플 형식으로 입력하십시오.
튜플에 대해서는 아래 설명을 참조하십시오. (변수에 여러 항목을 넣을 때 튜플을 사용할 수 있습니다.)
https://www.w3schools.com/python/python_tuples.asp
파이썬 튜플
W3Schools는 웹의 모든 주요 언어로 무료 온라인 자습서, 참조 및 연습을 제공합니다. HTML, CSS, JavaScript, Python, SQL, Java 등과 같은 인기 있는 주제를 다룹니다.
www.w3schools.com
그리고 while 문의 :=는 2019년 10월에 도입된 새로운 Python 구문으로, 더 큰 표현식의 일부로 변수에 값을 할당합니다. 그리고 다시. 그의 별명은 해마 운영자입니다.
https://docs.python.org/3/whatsnew/3.8.html
파이썬 3.8의 새로운 기능
출판사, Raymond Hettinger,. 이 기사에서는 3.7과 비교하여 Python 3.8의 새로운 기능을 설명합니다. Python 3.8은 2019년 10월 14일에 릴리스되었습니다. 자세한 내용은 변경 로그를 참조하십시오. 요약 – 간행물…
docs.python.org
간단히 말해서 할당과 반환을 모두 수행하는 연산자입니다.
(Python) 유용한 새 연산자! 해마 연산자 := (해마 연산자)
Python 3.8부터 해마 연산자(:=)가 도입되었습니다. 최근에 알게 된 아주 알려지지 않은 연산자입니다. 간단히 말해서 할당과 반환을 모두 수행하는 연산자입니다. 개념, 목적 및 예
bio-info.tistory.com
다음 yield 키워드는 결과 값을 반환하는 키워드입니다.
yield는 생성기를 반환합니다.
자세한 내용은 다음 문서를 참조하십시오.
https://www.daleseo.com/python-yield/
Python의 yield 키워드 및 생성기
Dal Seo의 엔지니어링 블로그
www.dalseo.com
https://realpython.com/introduction-to-python-generators/
파이썬에서 제너레이터와 수율 사용하기 – Real Python
이 단계별 튜토리얼에서는 Python의 제너레이터 및 yielding에 대해 배웁니다. 여러 Python yield 문을 사용하여 생성기 함수 및 생성기 표현식을 생성합니다. 또한 다음을 활용하는 데이터 파이프라인을 만드는 방법을 배웁니다.
realpython.com
궁극적으로 yield batch의 의미는 입력 컨텍스트 it을 입력 정수 n의 크기로 나눈 결과인 배치를 반환하는 것입니다.
즉, 큰 데이터를 특정 크기의 덩어리로 나누는 값입니다.
이제 이 값을 토큰화한 다음 청크로 분할합니다.
def chunked_tokens(text, encoding_name, chunk_length):
encoding = tiktoken.get_encoding(encoding_name)
tokens = encoding.encode(text)
chunks_iterator = batched(tokens, chunk_length)
yield from chunks_iterator이에 대한 함수 이름은 chunked_tokens()이고 3개의 입력을 받습니다.
get_encoding()으로 인코딩 설정
encode()로 토큰을 할당합니다. (이 부분은 위에서 다뤘습니다.)
그런 다음 위에서 만든 batched() 함수를 사용하여 청크 값을 받아 chunks_iterator에 할당합니다.
그리고 이 chunks_iterator를 yield와 함께 반환합니다.
이제 마지막 손질을 하는 함수를 만들어 봅시다.
import numpy as np
def len_safe_get_embedding(text, model=EMBEDDING_MODEL, max_tokens=EMBEDDING_CTX_LENGTH, encoding_name=EMBEDDING_ENCODING, average=True):
chunk_embeddings = ()
chunk_lens = ()
for chunk in chunked_tokens(text, encoding_name=encoding_name, chunk_length=max_tokens):
chunk_embeddings.append(get_embedding(chunk, model=model))
chunk_lens.append(len(chunk))
if average:
chunk_embeddings = np.average(chunk_embeddings, axis=0, weights=chunk_lens)
chunk_embeddings = chunk_embeddings / np.linalg.norm(chunk_embeddings) # normalizes length to 1
chunk_embeddings = chunk_embeddings.tolist()
return chunk_embeddingsnumpy 모듈을 가져옵니다.
그리고 len_safe_get_embedding()이라는 함수를 만듭니다.
입력 값은 텍스트, 모델, max_tokens 및 인코딩 이름입니다.
위에서 만든 함수에서 사용되는 모든 값입니다.
먼저 chunk_embeddings 및 chunk_lens라는 목록을 초기화합니다.
(참고로 파이썬에서 ()는 배열 리스트, ()는 튜플, {}는 딕셔너리입니다.)
(Python) Python에서 (), (), {} 사용
(), (), {} Python 배열 튜플 사전 {사전} 선언에서 사용 arr = () tup = () dic = {} 초기화 arr = (1, 2, 3, 4) tup = (1, 2, 3 , 4) dic = {“1월”:1, “2월”: 2, “3월”:3 } load arr(0) tup(0) dic(“3월”)
gostart.tistory.com
그런 다음 위에서 만든 chunked_tokens() 함수가 반환한 배열 수만큼 for 루프를 반복합니다.
배열(목록)의 각 요소에 대해 chunk_embeddings.append()를 실행하여 위에서 초기화한 chunk_embeddings 배열에 개별적으로 추가합니다.
입력 값은 get_embedding()이며 openai API openai.Embedding.create()에서 얻은 각 요소에 대한 임베딩 값입니다.
chunk_embeddings는 이제 openai의 임베딩 값을 포함합니다.
그리고 chunk_lens 배열에 각 청크의 길이를 배열로 추가합니다.
for 문 다음에는 if 문이 옵니다.
if average: 는 위에서 average= true로 정의되어 있으므로 무조건 실행됩니다.
if 문 내부를 살펴보면 먼저 위에서 얻은 chunk_embeddings 배열의 각 항목에 대한 임베딩 값의 평균값을 찾습니다.
다른 매개 변수 축 및 가중치는 아래를 참조하십시오.
https://numpy.org/doc/stable/reference/generated/numpy.average.html
numpy.average — NumPy v1.24 매뉴얼
지정된 축을 따라 평균을 반환합니다. 반환 값이 True이면 첫 번째 요소는 평균이고 두 번째 요소는 가중치 합인 튜플이 반환됩니다. sum_of_weights는 retval과 같은 유형입니다. dtype 결과는 일반 패턴을 따릅니다.
numpy.org
이러한 평균값을 정규화합니다.
https://numpy.org/doc/stable/reference/generated/numpy.linalg.norm.html
numpy.linalg.norm — NumPy v1.24 매뉴얼
(1) GH Golub 및 CF Van Loan, Matrix Computations, Baltimore, MD, Johns Hopkins University Press, 1985, pg. 15
numpy.org
그리고 마지막으로 해당 chunk_embeddings 값을 리스트 형식으로 변환한 후 반환합니다.
받은 임베딩 값을 여러 청크로 나누어 평균화하고 정규화하여 리스트까지 만들었습니다.
average_embedding_vector = len_safe_get_embedding(long_text, average=True)
chunks_embedding_vectors = len_safe_get_embedding(long_text, average=False)
print(average_embedding_vector)
print(chunks_embedding_vektor)
이제 청크로 분할하여 위에서 만든 long_text 포함 값을 가져옵니다.
average_embedding_vector는 평균을 true로 설정하고 평균을 얻습니다.
그리고 chunk_embedding_vectors는 평균화하지 않은 값을 보여줍니다.
average_embedding_vector는 다음과 같습니다.

1536개의 정수가 포함된 포함 값입니다.
그런 다음 평균화하지 않고 chunks_embedding_vectors.

똑같아 보이지만 사전 평균화 값이므로 임베딩 값이 여러 개 있습니다.
한 번은 Notepad++에서 번호를 검색했습니다.
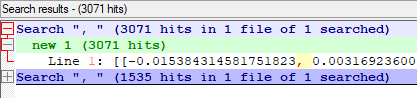
평균이 1535이므로 합계가 임베딩 값인 1536임을 알 수 있다.
쉼표의 수를 평균화하지 않은 두 번째는 3071이므로 여기에 2개의 덩어리가 있음을 알 수 있습니다.
예에서와 같이 길이를 출력했습니다.

보고 있자니 설명이 나왔다.
average=True인 경우 1536 차원(Dimension) Embed가 결과값
average=False의 경우 두 개의 임베딩 벡터가 있으며 두 개의 청크가 있기 때문입니다.
요약
오늘 배운 것은 각 모델에서 허용하는 입력값 크기보다 입력값이 클 때 사용하는 방법입니다.
첫 번째 방법은 가능한 한 많은 값을 취하고 나머지는 자르는 것입니다.
두 번째는 가능한 한 많은 청크로 나누고 각 청크에 대한 임베드 값을 개별적으로 얻는 것입니다.
그리고 이러한 각 임베딩 값은 numpy의 average() 함수를 사용하여 평균화할 수 있습니다.
오늘은 입력값에 토큰이 많아 청구금액이 조금 높았습니다. 3센트(50원)